Text AI framework
분석·추론·생성까지 이어지는 프레임워크
텍스트 데이터를 대상으로 AI 프레임워크를 적용하고, 이를 기반으로 분석, 추론, 생성 기능을 구현합니다.
- 학습데이터 구축 및 파라미터 튜닝
- 텍스트 기반 분석, 추론, 생성 적용
- 고객 도메인에 맞는 문제 정의와 모델 전략 수립
아울네스트의 기술은 모델 하나를 소개하는 데서 끝나지 않습니다. 데이터 수집, 자연어 처리, 추론, 시각화, 보고, 권한·감사까지 연결되는 전체 아키텍처를 설계합니다. 고객 환경에 맞는 정확도와 설명 가능성, 운영 가능성을 함께 확보해 기술이 실제 제도와 업무 속에서 오래 작동하도록 만드는 것이 기준입니다.
아울네스트는 텍스트 AI 코어, 리스크 모니터링, 보안 확장 기술, 폐쇄망 분석 체계까지 고객 환경에 맞춰 설계합니다.
텍스트 분석·추론·생성, 학습데이터 파라미터 튜닝, 패러프레이즈 탐색
NLP-Mainframe 기반 전처리, 형태소·구문 분석, 개체명 인식, 자동 띄어쓰기
감성분석, 리스크 추출, 전파 경로 분석, 토픽 라벨링, 택소노미 자동분류
보안 로그 분석, 위협 인텔리전스, 피싱·스미싱·악성 URL 탐지, 위험도 스코어링

텍스트 데이터 기반 AI 프레임워크, NLP-Mainframe, 리스크 모니터링, 택소노미 자동분류, 토픽 레이블러, 감성분석 시스템은 모두 개별 기능이 아니라 연결된 체계로 작동합니다.
텍스트 데이터를 대상으로 AI 프레임워크를 적용하고, 이를 기반으로 분석, 추론, 생성 기능을 구현합니다.
자동 띄어쓰기, 오탈자 교정, 형태소 분석, 구문 분석, 개체명 인식, 패러프레이즈 탐색으로 분석 정확도를 높입니다.
감성사전과 균형 코퍼스를 기반으로 메시지 군집, 작성자, 게시채널, 전파 경로를 분석해 조기 신호를 포착합니다.
IRX AI 제품군은 멀티모달 데이터 수집, LLM 설명 인터페이스, 위험 예측, 서비스 워크플로우 설계를 결합한 구조입니다. 음성·영상 응급 분류, rPPG, 안면 비대칭 판별, 웨어러블 분석, OCR/NLP 보험 재설계는 모두 아울네스트가 축적한 텍스트 AI와 운영형 아키텍처 원칙 위에서 구성됩니다.
증상 설명, 영상, 생체신호를 결합해 중증도 분류와 대응 가이드를 산출합니다.
비접촉 생체신호와 안면 비대칭 추정을 통해 응급 판단의 근거를 보강합니다.
심박수, 수면, 걸음수, 식이 로그를 건강 점수와 행동 권장으로 변환합니다.
보험증서와 검진결과 이미지를 OCR/NLP로 해석해 리디자인 시나리오와 설명을 생성합니다.
헬스케어 도메인에서도 핵심은 센서가 아니라 운영 구조입니다. 데이터 수집, 위험 예측, 설명 가능한 UI, 보장 실행까지 이어질 때 비로소 제품이 됩니다.


아울네스트의 Technology는 감성 어휘 자원, 한국어 전처리, 병렬 인덱싱, 상관·토픽 모델링, Claim–Evidence 연구가 누적된 결과입니다. 이 연구의 깊이는 기술의 정교함과 설명 가능성뿐 아니라 산업 적용 가능성과 사업의 지속성까지 함께 높입니다.
감성 어휘 자원, 자동 띄어쓰기, 병렬 인덱싱은 한국어 비정형 문서 전처리와 검색 기반의 안정성을 결정합니다.
상관 추출과 토픽 모델링 연구는 메시지 구조를 정량적으로 해석하고 운영형 지표로 전환하는 데 핵심적입니다.
Sentence Structure, Proposition, Epistemic Operator, Claim–Evidence Graph, Epistemic State 연구는 최신 Technology 축을 형성합니다.
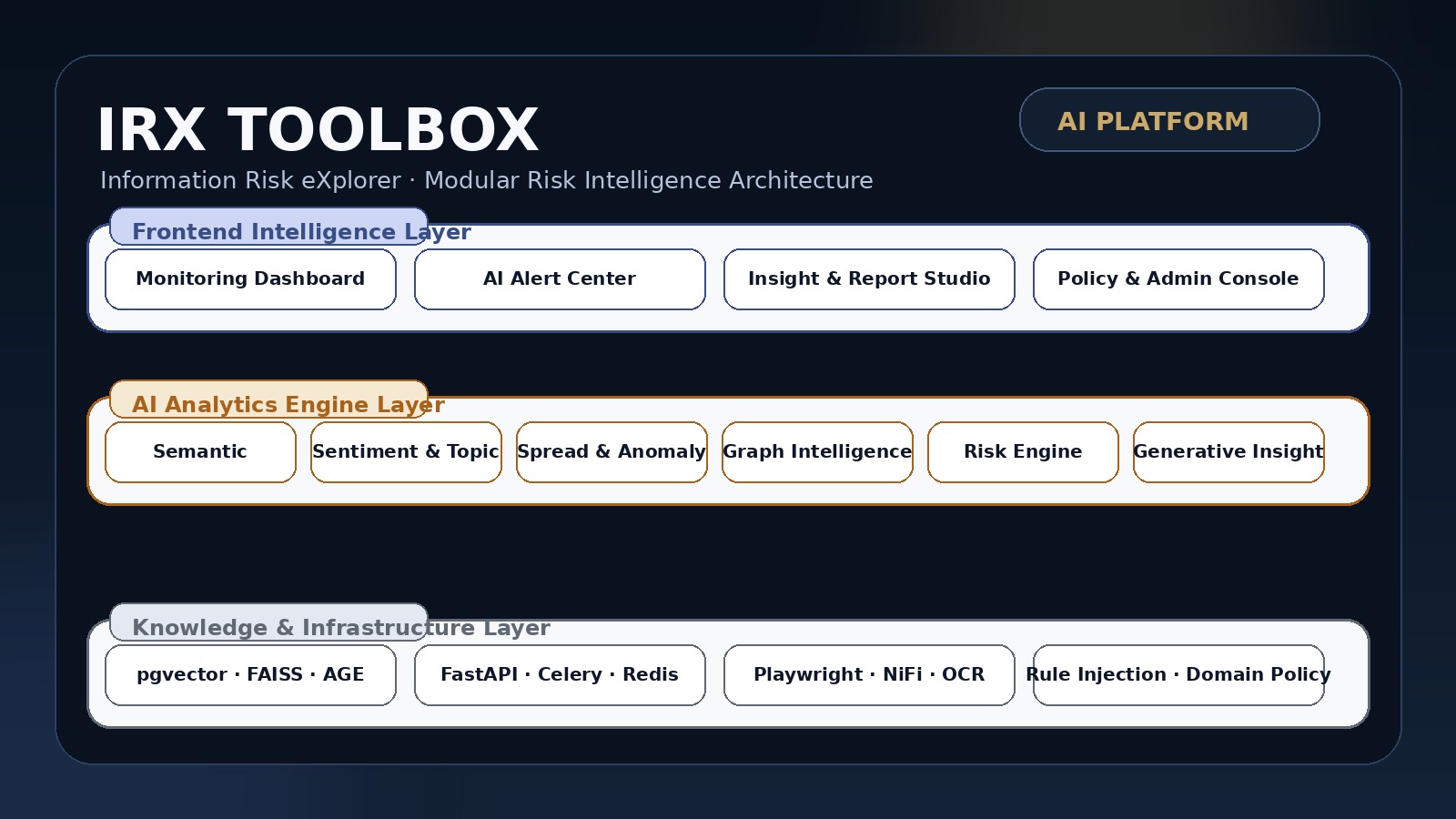
IRX Toolbox는 공통 AI Core Engine 위에 Rule Injection과 Domain Policy Layer를 결합해, 브랜드 보호, 인포데믹 대응, 평판 분석, 보안 위협 분석처럼 서로 다른 과제를 같은 구조적 문법 안에서 다룰 수 있게 설계한 프레임워크입니다. 핵심은 모델 하나를 강조하는 것이 아니라, 의미 분석, 감성·토픽 분석, 확산·이상 탐지, 그래프 인텔리전스, 생성형 인사이트를 하나의 실행 흐름으로 통합해 실제 서비스와 사업의 형식으로 이어지게 하는 데 있습니다.
뉴스 · SNS · 리뷰 · 게시글 텍스트 데이터
로고 · 패턴 · 멀티모달 학습용 이미지
Risk 판정 · 대응 사례 데이터베이스
계정 · 게시물 관계 네트워크 구조 데이터
각 에이전트는 독립 모듈이면서도 같은 데이터 파이프라인과 정책 레이어를 공유합니다. 그래서 도메인이 달라도 판정 근거, 위험도, 보고 체계가 동일한 기준으로 운영됩니다.
게시물·기사·리뷰 본문에서 Claim·Topic·Entity를 추출하고, 약어·변형·오타까지 Transformer 기반 의미 인식으로 해석합니다.
LLM과 Transformer를 결합해 의미 중심 감성 분석과 Hybrid Topic Modeling을 수행합니다.
Spike Detection과 Multi-Factor Diffusion Model을 통해 초기 확산 위험을 조기 경보합니다.
계정·게시물·이슈 간 관계 그래프를 생성하고 영향력, 커뮤니티, 전파 구조를 시각화합니다.
핵심 이슈, 감성 변화, 확산 위험을 요약하고 대응 전략과 정책 권고안을 자동 생성합니다.
도메인마다 프로젝트를 새로 짜는 대신, 공통 코어 위에 정책과 규칙을 주입해 재구성 속도와 유지보수성을 동시에 확보합니다.
의미 분석, 감성·토픽 분석, 확산 예측, 그래프 구조 해석, 생성형 인사이트, 전체 플랫폼 아키텍처를 각각 독립된 설계 문서로 유지하고 있습니다. Technology 페이지에는 여섯 개 문서를 모두 인용해 기술 근거를 직접 확인할 수 있게 두었습니다.
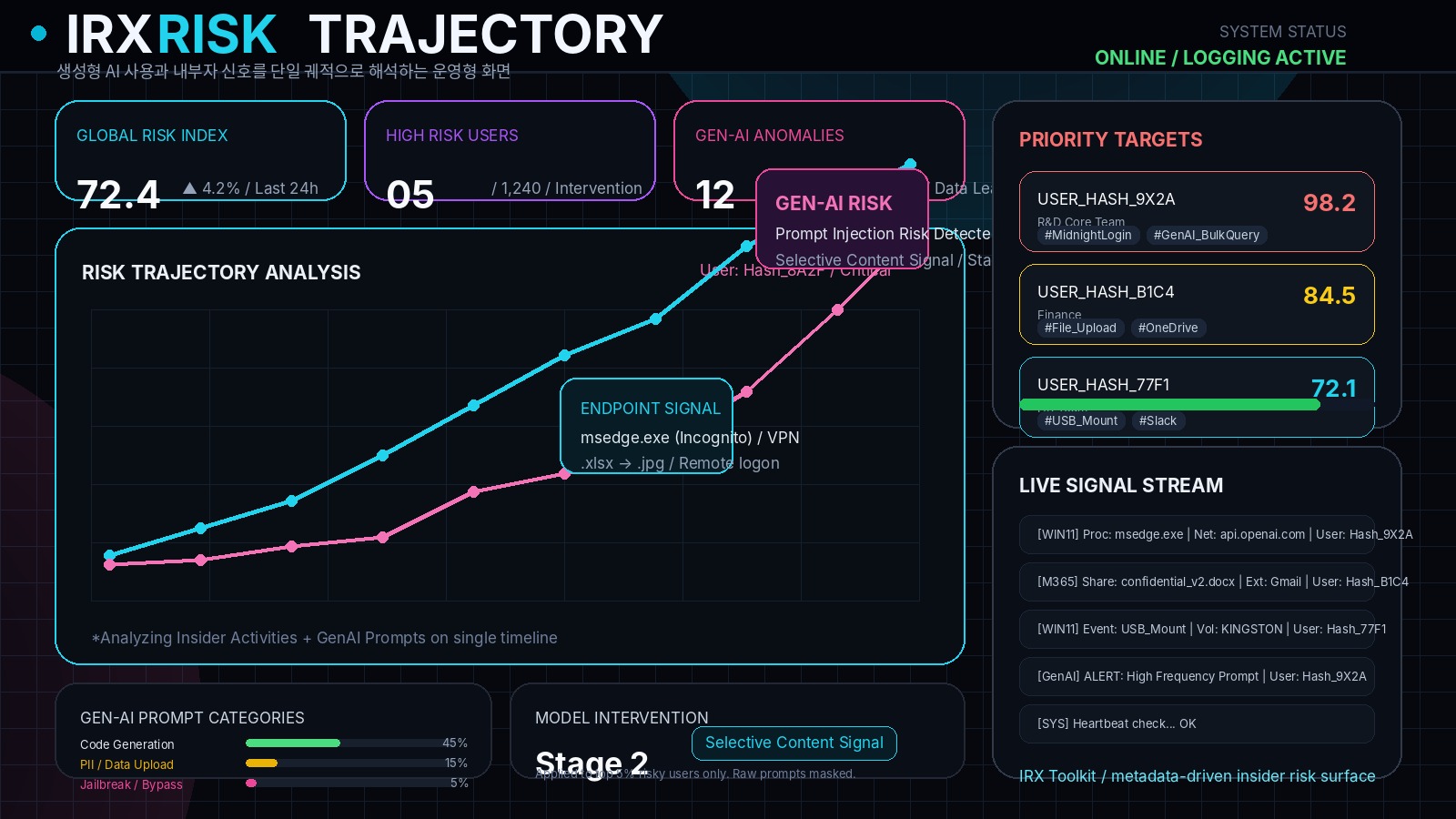
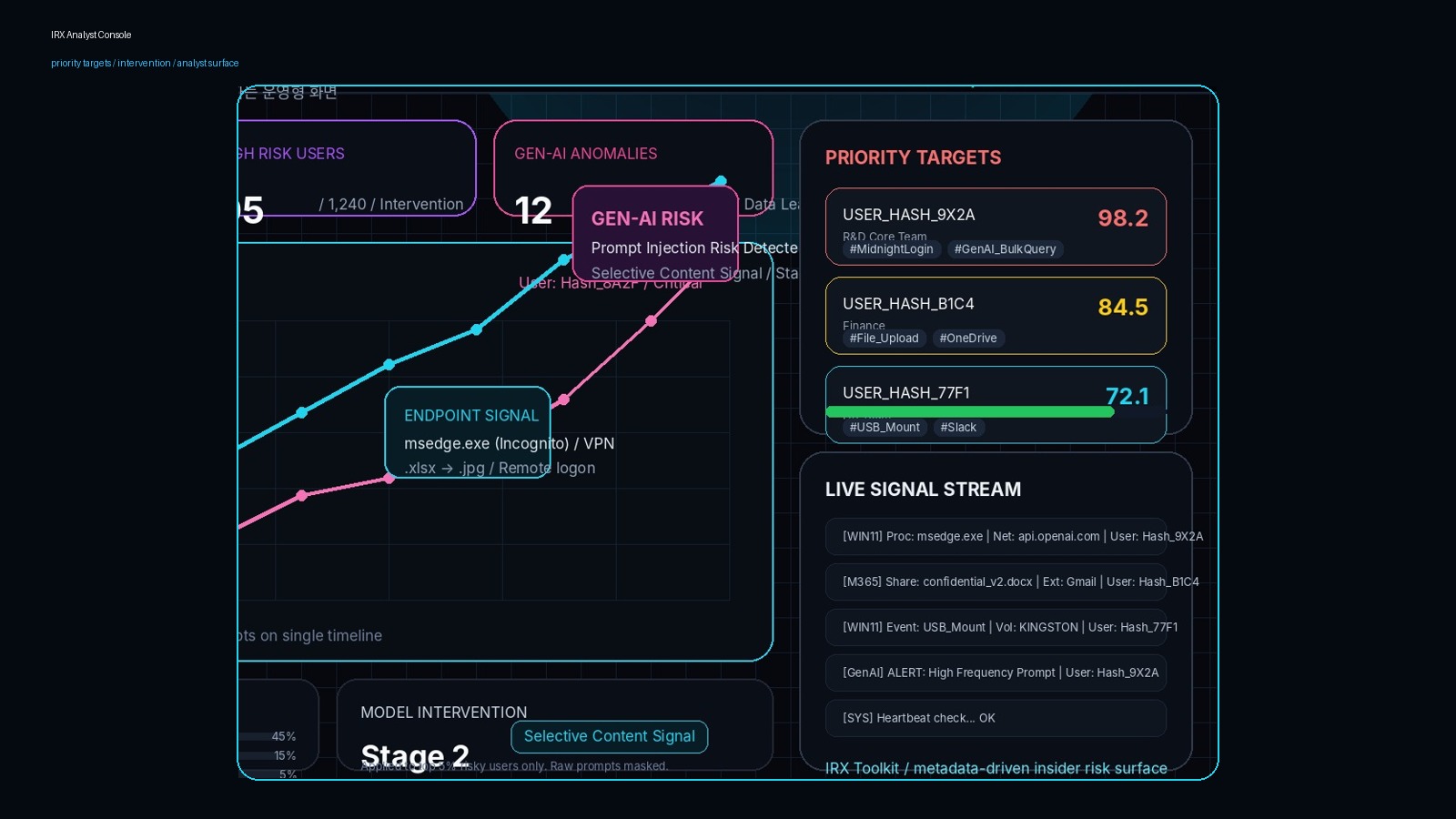
IRX Toolbox의 Spread & Anomaly, Graph Intelligence, Generative Insight 구조는 실제 운영에서는 metadata-first risk trajectory, priority target console, prompt inspector, endpoint trace, legal-grade report export로 나타납니다. 이 아카이브는 생성형 AI 사용과 내부자 위험을 같은 시간축에서 읽고, 필요한 대상에만 선택적으로 개입하는 단계형 운영 논리를 보여줍니다.
PII hashing, content logging 제한, hashed identifier 기반 탐지로 프라이버시를 보존한 채 초기 위험 사용자를 선별합니다.
상위 위험 사용자에 대해서만 prompt·payload·파일 이동 흔적을 제한적으로 추가 분석해 개입 범위를 최소화합니다.
Prompt category, 프로세스 트리, 파일명 변경, 외부 이메일, 클라우드 업로드, USB 신호를 단일 궤적으로 결합합니다.
Encrypted report, timeline extract, masked summary, intervention playbook, SAM3 시각 검증 로그까지 같은 체계로 연결합니다.
공공보건형 인포데믹 대응은 단일 키워드가 아니라 연결된 개념 클러스터를 해석해야 합니다. 아울네스트는 이미지와 영상의 OCR, 음성의 STT, 텍스트 Claim을 함께 수집하고, 이를 Narrative·Evidence·Channel·Community·Risk·Response 관계로 연결해 어떤 서사가 어디서 먼저 번지는지와 어떤 대응을 우선해야 하는지를 동시에 파악하게 합니다.
mRNA 백신 부작용 과장, 이물질 음모론, 가짜 치료제, 정책 불신, 임신부·소아 거부처럼 반복 출현하는 서사 묶음을 연결 구조로 추적합니다.
텍스트, 이미지, 영상, 음성, OCR, STT 신호를 함께 분석해 주장과 증거의 연결 강도를 높이고 설명 가능성을 확보합니다.
질병·백신·치료제 엔터티를 명시형 스키마로 정리하면서, 대형 언어 모델의 암묵적·통계적 관계망으로 서사 활성화를 함께 해석합니다.
사후 반박만이 아니라 사전반박, 리터러시 강화, 긍정 서사 전환, 커뮤니티 설명, 플랫폼 개입까지 대응 워크플로우에 포함합니다.
Claim · Narrative · Evidence · Community · Risk · Response
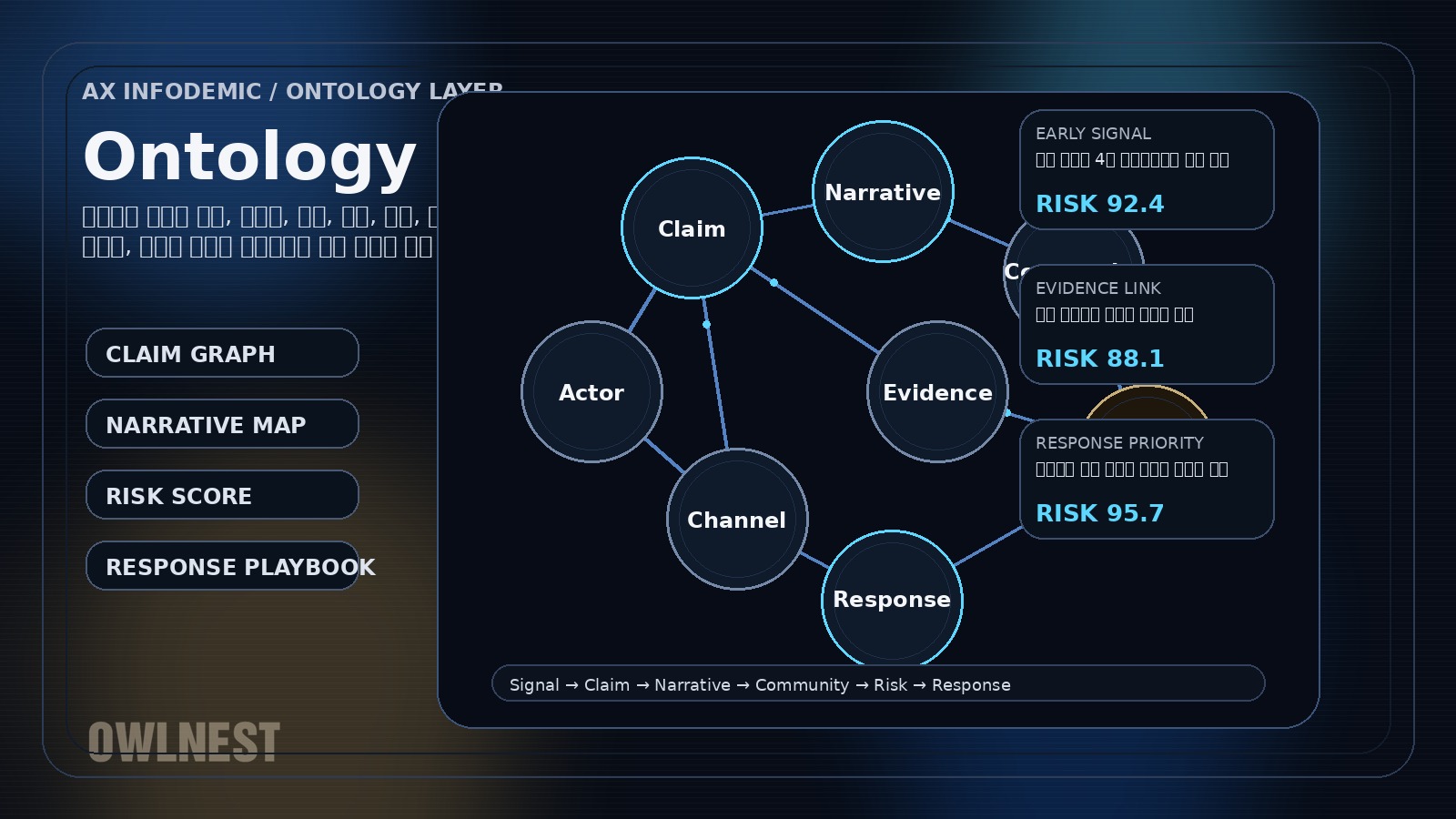
운영 환경에서는 두 방식이 경쟁하지 않습니다. 엔터티, 관계, 규칙은 명시형 스키마로 관리하고, 서사 확산과 연관성 활성화는 암묵형 관계망으로 해석해야 실제 대응 속도가 나옵니다.
질병, 백신, 치료제, Claim, Source, Fact, Risk, Response 엔터티를 명료하게 정의하고 감사 가능한 기준을 마련합니다.
대형 언어 모델의 가중치와 임베딩 공간에서 형성된 통계적 관계망을 이용해 어떤 클러스터가 함께 활성화되는지 파악합니다.
| 항목 | 전통적 온톨로지 | 운영형 LLM/개념 클러스터 온톨로지 |
|---|---|---|
| 저장 방식 | 명시적 저장트리플 구조와 엔터티·관계 정의를 기반으로 스키마를 통제합니다. | 분산된 관계 압축신경망 가중치와 임베딩 공간에서 패턴·연관성·확률적 연결을 활용합니다. |
| 추론 방식 | 형식적 추론규칙 기반 일관성 검증과 제약 관리에 강합니다. | 암묵적 추론자연어 문맥과 서사 연쇄를 바탕으로 연결 클러스터를 빠르게 활성화합니다. |
| 장점 | 엄밀함과 감사성규제, 보고, 검수, 기준 문서화가 필요한 환경에서 유리합니다. | 유연성과 커버리지새로운 표현, 밈, 변형된 루머, 복합 서사를 조기에 감지하기 좋습니다. |
| 운영 역할 | 기준선엔터티와 관계 정의, 검수 기준, 설명 구조를 담당합니다. | 탐지선클러스터 활성화, 확산 경로, Prebunking 우선순위 선정을 담당합니다. |
허위정보가 자리 잡은 뒤 하나씩 반박하는 구조만으로는 운영 비용이 커집니다. 따라서 조기 탐지와 함께 사전반박, 리터러시 강화, 긍정 서사 전환, 커뮤니티 설명, 플랫폼 개입을 하나의 전략 체계로 묶습니다.
고위험 서사가 확산되기 전에 미리 논리 오류와 사실 구조를 알려주는 예방형 전략입니다.
사용자와 현업 담당자의 정보 판단 역량을 높여 루머의 설득력을 낮춥니다.
공포 서사를 그대로 반박하는 대신, 공공 신뢰와 보호의 관점으로 이야기 구조를 재설계합니다.
지역 의료진, 교사, 담당 공무원, 신뢰 가능한 커뮤니티 리더를 통해 설명의 신뢰도를 높입니다.
플랫폼 알림, 자동 추천, 우선 노출, 경고 메시지 등 채널 차원의 개입 포인트를 설계합니다.
사후 반박은 여전히 필요하지만, 전체 전략에서는 후속 정정과 공식 기록의 역할로 위치시킵니다.
아울네스트는 종합 텍스트 AI 보안 시스템 기술 축도 함께 제공합니다. 로그 분석, 위협 인텔리전스, 피싱 탐지, 상관분석, 비식별화, 위험도 스코어링이 이 범주에 포함됩니다.
인증, 접근, 권한, 네트워크, 시스템 로그를 표준 스키마로 정규화하고 계정·단말·IP·시간대 기반 이상징후를 탐지합니다.
IOC 자동 수집과 중복 제거, 텍스트 리포트 내 TTP·취약점·CVE 추출, 출처 신뢰도 및 최신성 기반 우선순위 큐레이션을 수행합니다.
메시지 본문 특징 분석과 URL/도메인 패턴 점검, 유사 브랜드 사칭 탐지, 의심도 기반 차단 및 경고 문구 자동 생성을 결합합니다.
단일 경보가 아니라 연쇄 이벤트 단위로 공격 흐름을 구성하고, 그래프 상관분석과 전형 시나리오 매칭으로 설명 근거를 제공합니다.
문서·대화·게시글 등 비정형 데이터에서 민감정보를 분류하고, 마스킹 규칙과 적용 로그를 함께 관리합니다.
자산 중요도와 노출도, 실제 악용 여부를 반영해 우선순위를 재정렬하고, 조치 전후 리스크 변화를 대시보드와 리포트로 추적합니다.
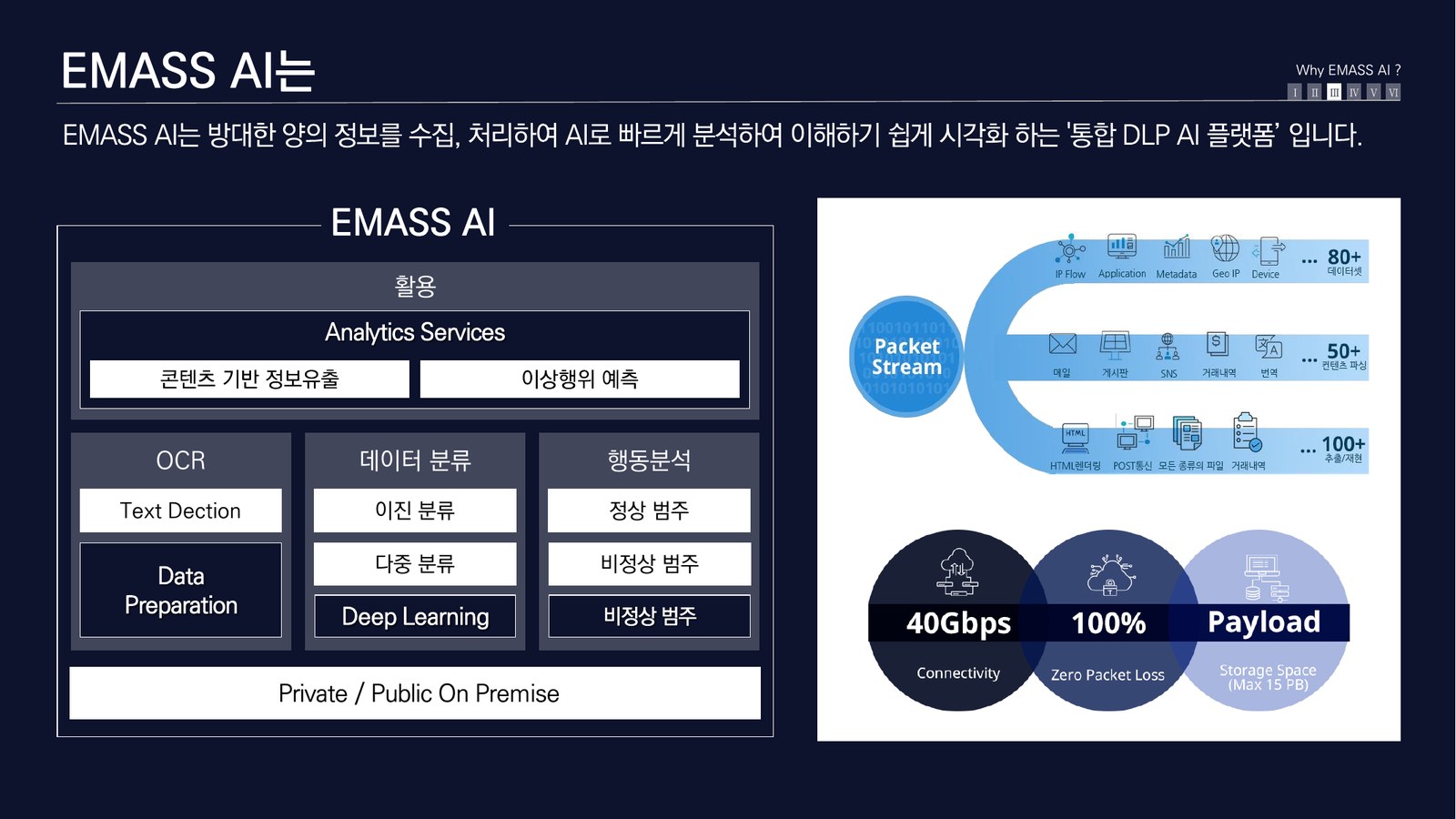
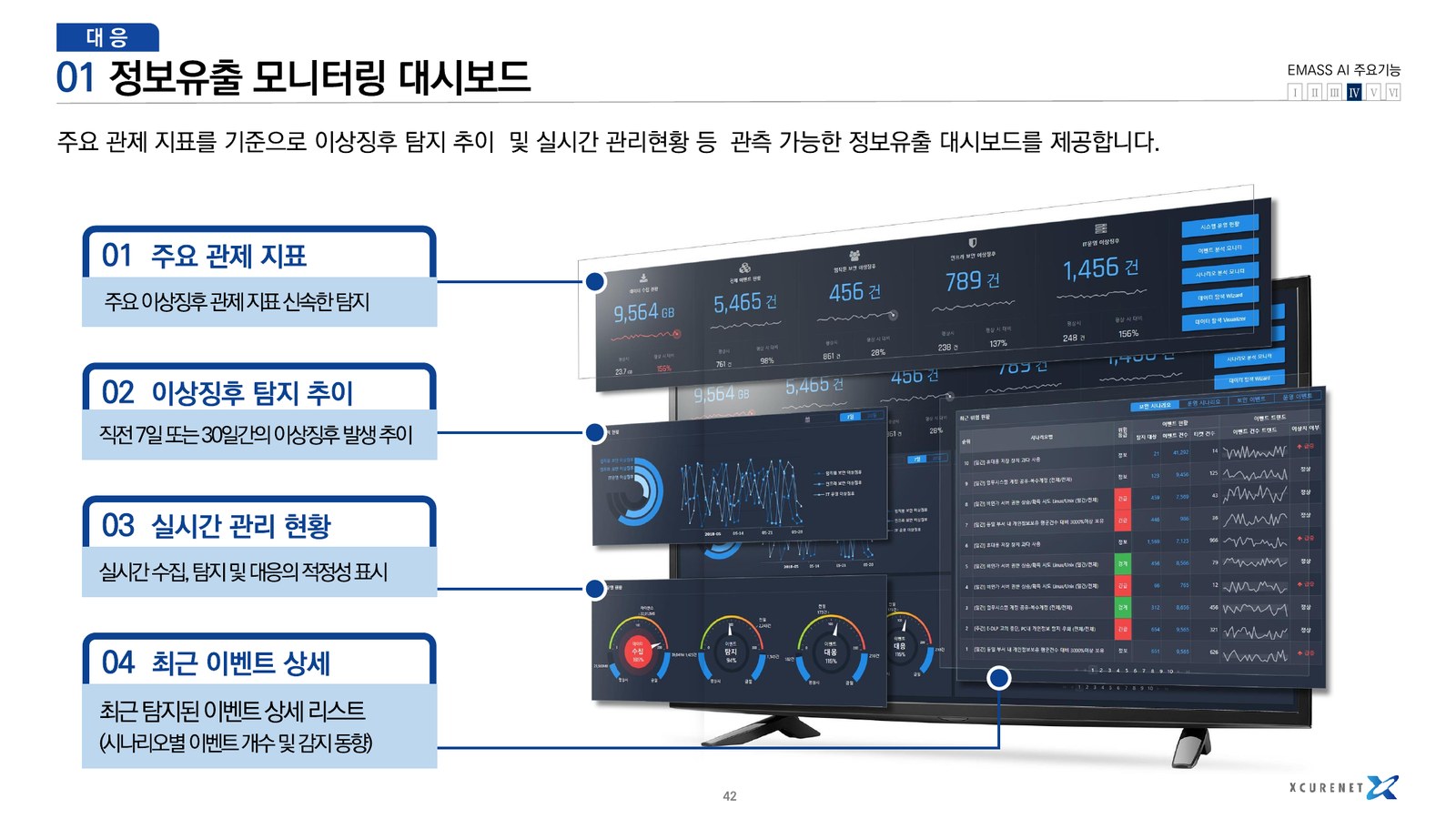
EMASS AI는 단일 룰 기반 차단기가 아니라 콘텐츠 단위 유출 위험 감지, 사용자 행동 분석, 정보유출 모니터링, AI OCR·딥러닝 피드백 자동화를 하나의 DLP AI 아키텍처로 묶습니다. 대규모 풀패킷과 메일·첨부파일·메신저 콘텐츠를 함께 해석하고, 실무자가 해석 가능한 대시보드·스코어보드·경보 관리원장으로 연결하는 점이 핵심입니다.
내용 기반 메일 위험도, 유사 메일 분석, 수신처 오지정, 스테가노그라피 탐지를 하나의 위험 엔진으로 묶습니다.
웹 서비스 패킷, 메일·첨부파일, 조직 네트워크, 시계열 이력을 바탕으로 사용자 단위 혐의 점수를 계산합니다.
대시보드, 스코어보드, 메시지 검색, 관계분석, 경보 관리원장까지 탐지 이후 운영 화면을 함께 설계합니다.
PPT, EXCEL, HWP/DOC/PDF, 압축파일의 텍스트·표·도형·위치값을 추출해 분류 정확도를 높입니다.
다중 모델 결과 불일치와 피드백 루프를 활용해 운영 중에도 성능을 개선하는 구조를 갖습니다.
삼성전자 정보보호 환경처럼 보안·규제 요구가 큰 조직에서 온프레미스 중심으로 운영 가능한 구조입니다.
CTA Analysis Server는 단순한 시각화 도구가 아니라, 폐쇄망 환경에서 대용량 비정형 데이터를 빠르게 분석하고 운영까지 연결하는 하이브리드 체계입니다.
Rocky Linux 8.10, PostgreSQL ODS/DW 분리 구조, 커넥션 풀링을 적용한 안정적 런타임
Python 3.11, C++ Native, Legacy Python 2.7을 결합하고 ctypes FFI로 zero-copy에 가까운 고속 처리를 구현
Z-Score 기반 동시출현 네트워크, LDA 토픽 모델링, KoBART 생성형 요약, 사용자 사전 자동 갱신
39개 부대 기준 통계·트렌드·네트워크·일간보고·지도 기반 분석·권한·데이터·감사 로그 관리
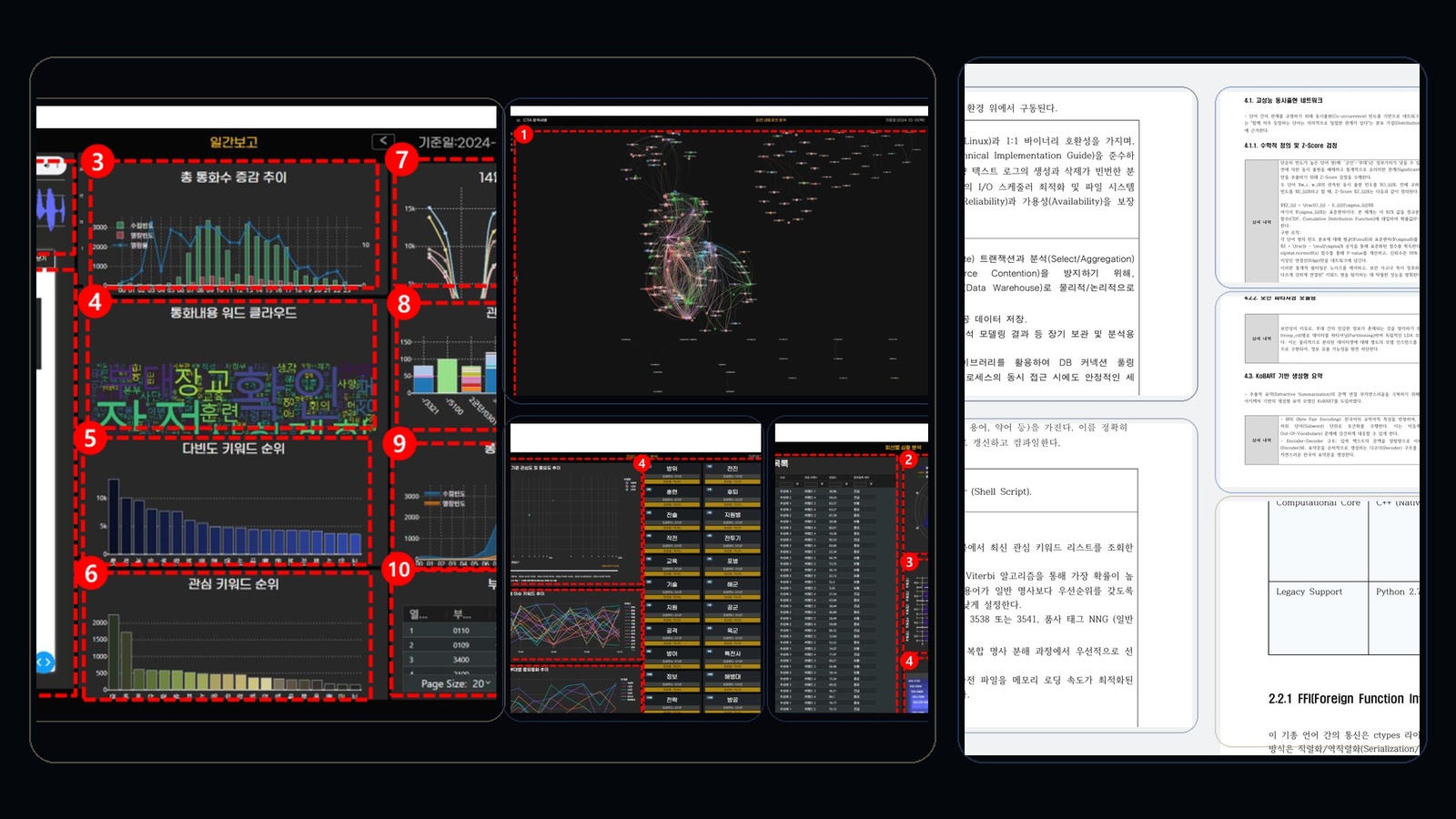
사전 구축 → 수집/전처리 → 심층 분석 → 시각화/요약의 5단계 자동화 워크플로우를 구성합니다.
부대별 통화 통계, 트렌드, 네트워크, 주요 상황, 일간보고, 지도 기반 분석, 키워드·주제·회선별 심층 분석을 제공합니다.
키워드 관리, 권한 관리, 데이터 관리, 감사 로그까지 포함되어 장기 운영에 적합합니다.
멀티프로세싱, 배치 트랜잭션, 직렬화 최적화를 통해 폐쇄망 환경의 리소스 제약을 극복합니다.
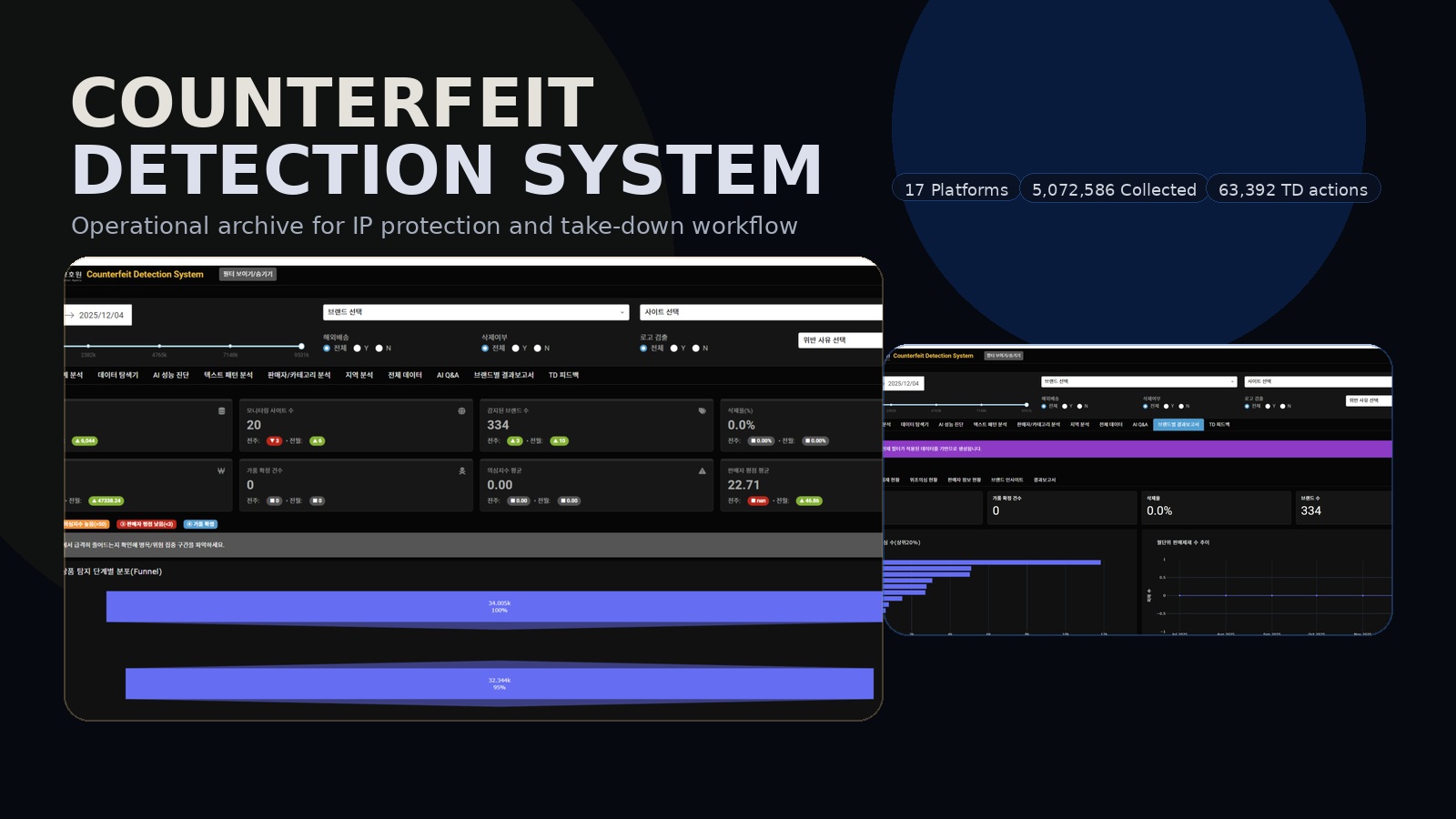
CDS는 데이터 수집만 하는 시스템이 아닙니다. 다중 플랫폼에서 데이터를 모으고, AI가 의심·위험지수를 산출하고, 전문가가 검수하고, 브랜드별 결과 보고서와 판매 제재 요청까지 이어지는 구조를 갖습니다.
17개 플랫폼에서 5,072,586건을 수집하고 플랫폼·브랜드별 실적을 체계적으로 축적
OCR 텍스트·로고 감지, 비생산품목 판별, AI 챗봇 증거 수집, 이미지 유사도 분석, 의심·위험지수 산출
BERT 기반 품목 분류기와 GPT 기반 정량 분석 정밀화를 통해 위조 탐지 정확도를 고도화
통계 분석, 데이터 탐색기, AI 성능 진단, AI Q&A, 브랜드별 결과 보고서, TD 피드백 모듈까지 제공
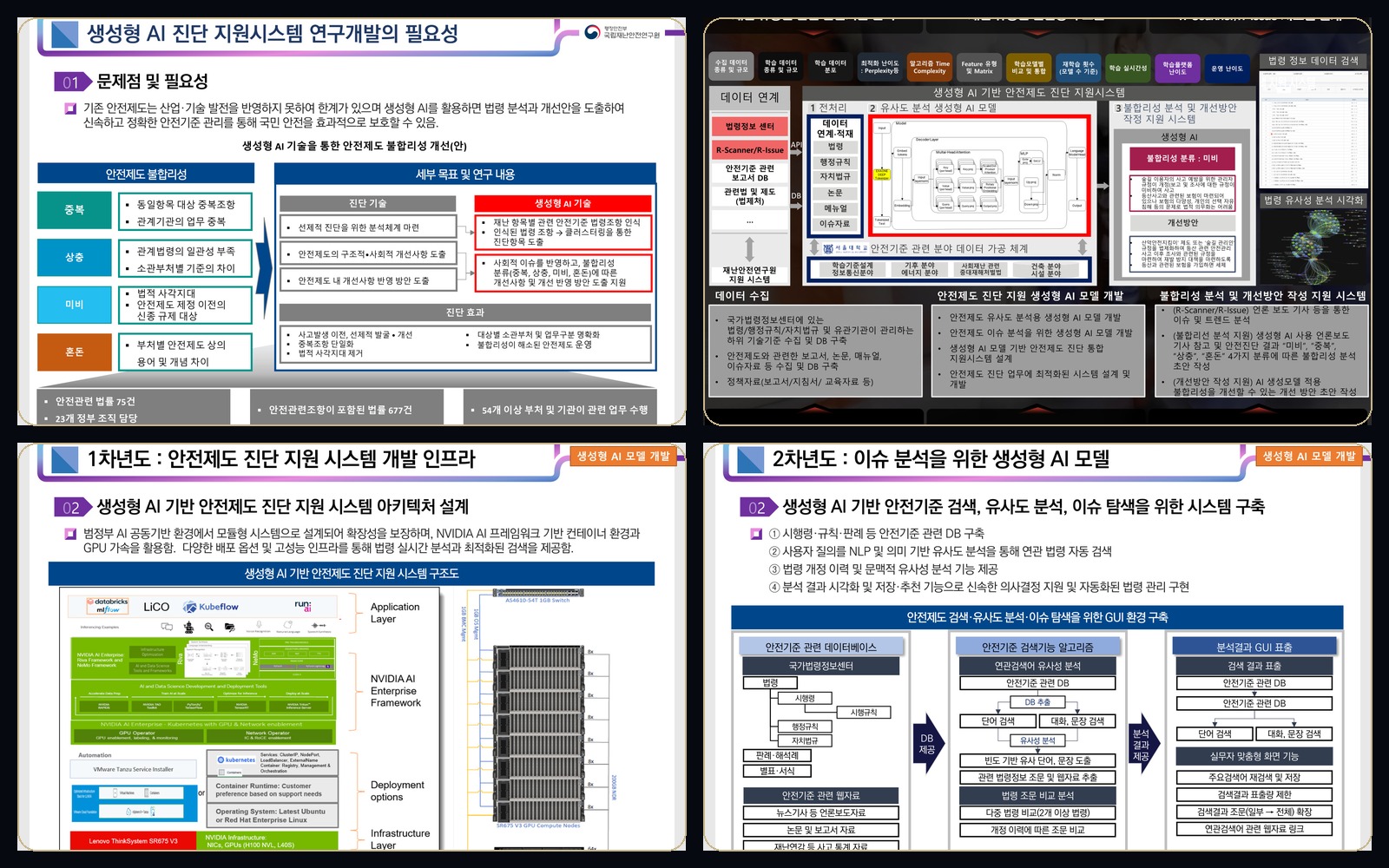
R-Scanner와 생성형 AI 기반 안전제도 진단 지원시스템은 공공기관이 실제로 요구하는 기술의 조건을 가장 정직하게 드러냅니다. 실시간성, 설명 가능성, 검색 품질, 비교 분석, 유지관리, 보안, GUI, 현장 실증까지 모두 갖춰져야만 현업이 움직입니다.
국내외 재난안전 정보 검색, 국내·국외 뉴스 모니터링, 실시간 재난안전 언론 현황 서비스를 통합했고, 중앙재난안전상황실에서 실제 활용된 공공 운영형 시스템입니다.
법령, 행정규칙, 자치법규, 하위 기술기준과 이슈자료를 통합 DB로 설계하고, 생성형 AI로 중복·상충·미비·혼돈을 선제적으로 진단하는 공공 규제형 AI 사례입니다.

고객이 실제로 검토하는 것은 모델의 이름보다 운영 구조입니다. 아울네스트는 데이터 구조, 권한 체계, 감사 요건, 보고 흐름, 사용자 이해 가능성을 함께 고려해 기술을 선택하고 설계합니다.
폐쇄망 여부, 데이터 갱신주기, 권한 체계, 감사 요구, 현업 보고 방식 같은 현실적 제약이 기술 설계의 출발점입니다.
결과가 왜 나왔는지, 어떤 신호가 유효했는지, 어떤 조치를 해야 하는지를 화면과 리포트에서 이해할 수 있어야 합니다.
프로젝트형 과제에서 쌓인 구조를 제품형 도입 옵션으로 재정리해, 고객이 장기 확장 전략까지 함께 검토할 수 있도록 합니다.