01 / Linguistic resource
감성 어휘 자원과 온톨로지의 기초
감성 어휘를 단순 목록이 아니라 재사용 가능한 의미 자원으로 설계해 의견 마이닝, 리스크 탐지, 인포데믹 구조화의 기반을 마련했습니다.
아울네스트의 Research는 기능 설명을 위한 부속 자료가 아닙니다. 언어자원 구축, 한국어 전처리, 병렬 인덱싱, 상관·토픽 모델링, 감성 온톨로지, Claim–Evidence 기반 인포데믹 연구를 장기적으로 축적해 왔고, 이 깊이가 새로운 과제를 빠르게 구조화하고 규제형·폐쇄망·공공 환경에서도 설명 가능한 운영 체계와 지속 가능한 사업의 형식을 제안할 수 있게 만듭니다.
초기 연구는 감성 어휘 자원과 한국어 전처리에서 시작됐고, 이후 상관·토픽 모델링, 현재는 Claim–Evidence·Epistemic 연구까지 확장됐습니다.
감성 어휘 사전, 의미 분류 행렬, 가중치 행렬, 온톨로지 매핑
자동 띄어쓰기, 병렬 인덱싱, 텍스트 전처리와 검색 기반
상관 추출, 토픽 분석, 형태적으로 풍부한 한국어 코퍼스 최적화
Sentence → Clause → Proposition → Epistemic State → Verification

언어자원 설계, 한국어 전처리, 대규모 병렬 처리, 상관·토픽 모델링, 감성·의미 가중치, Claim–Evidence 기반 검증 구조는 각각 독립된 성과이면서 동시에 하나의 기술 계보로 이어지고, 결국 제품과 서비스, 사업의 구조를 형성합니다.
감성 어휘를 단순 목록이 아니라 재사용 가능한 의미 자원으로 설계해 의견 마이닝, 리스크 탐지, 인포데믹 구조화의 기반을 마련했습니다.
자동 띄어쓰기, 병렬 인덱싱, 형태 처리 기반을 축적해 한국어 비정형 문서의 전처리·검색·분석 효율을 높였습니다.
상관 추출과 토픽 모델링을 통해 문서 집합의 잠재 구조를 정량적으로 해석하고, 운영형 지표로 연결할 수 있게 했습니다.
Sentence Structure, Epistemic Operator, Claim–Evidence Graph, Epistemic State, Prebunking을 하나의 대응 프레임으로 정리했습니다.
각 연구 자산은 단일 기능으로 소진되지 않습니다. 한국어 처리, 리스크 분석, 토픽 구조, Claim 검증, 대응 전략까지 여러 과제에서 반복적으로 재사용됩니다.
감성 어휘를 의미 분류와 의미 가중치가 결합된 계산 가능한 자원으로 구축한 연구입니다.

한국어 자동 띄어쓰기와 병렬 인덱싱 연구는 대용량 비정형 데이터 전처리·검색의 기초 인프라를 형성합니다.

상관 추출과 토픽 모델링 연구는 문서 집합의 잠재 구조를 운영형 분석 지표로 연결하는 통계 엔진입니다.
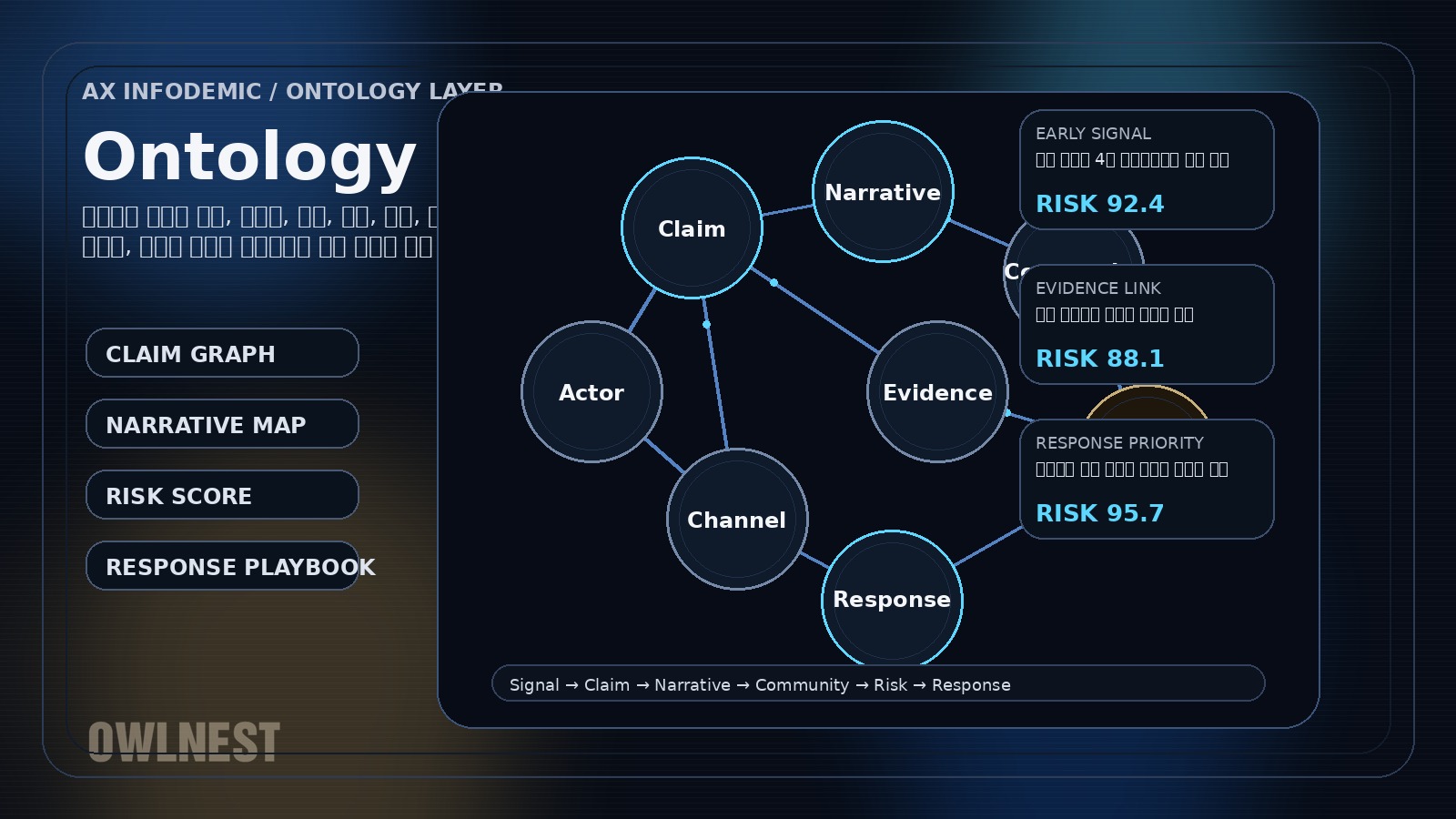
Claim–Evidence 구조화, Epistemic State, Causal Interface, Prebunking을 하나의 대응 프레임으로 엮은 현재의 선도 연구 축입니다.

형태 정보와 어휘 다양성을 고려한 렉심 중심 접근은 한국어 문서 분석의 노이즈를 줄이고 해석력을 높입니다.

아울네스트의 연구는 논문 발표로 끝나지 않습니다. 전처리, 검색, 상관, 토픽, Claim 검증, 지식 구조를 실제 화면과 워크플로우로 전환합니다.
아울네스트는 연구를 기술 설명과 제품 소개 사이의 공백을 메우는 보조 자료로 다루지 않습니다. 언어자원과 전처리 연구는 Technology를 안정화하고, 상관·토픽·Claim 연구는 운영형 분석 엔진을 정교하게 하며, 그 결과는 제품과 Actual Archives, 더 나아가 장기적으로 지속될 사업의 구조로 구현됩니다.
감성 어휘 사전, 자동 띄어쓰기, 병렬 인덱싱, 상관·토픽 모델링, Claim–Evidence 구조.
검색, 분류, 리스크 신호 추출, 토픽 구조화, 근거 연결, 대응 추천의 엔진으로 전환됩니다.
브랜드 보호, 국방형 분석, 공공 AX, 헬스케어 제품으로 이어지며, 고객이 직접 검토할 수 있는 구체적인 형태를 갖춥니다.
AX-인포데믹 시스템 매핑은 Ingestion, Epistemic Layer, Causal Structure, Intervention, Productization까지 이어지는 레이어를 정의하고, sentence_structure_parser, proposition_extractor, epistemic_operator_tagger, claim_evidence_graph_builder, epistemic_state_aggregator 같은 서비스 모듈로 연결합니다.
논문, 기술문서, 시스템 매핑 자료까지 함께 검토하시면 아울네스트의 기술이 어떤 연구 축적 위에 놓여 있는지 더 선명하게 확인하실 수 있습니다.